Die neue Dropbox-Suchmaschine Nautilus und ihre Architektur

In den vergangenen Monaten hat das auf die Suchinfrastruktur spezialisierte Entwicklerteam bei Dropbox mit Nautilus eine neue Volltext-Suchmaschine eingeführt, die unsere vorherige Suchmaschine ersetzt.
Aufgrund des schieren Datenvolumens bei Dropbox – wo wir mehrere hundert Milliarden Dateien speichern – sowie aufgrund der Notwendigkeit, jedem unserer mehr als 500 Millionen registrierten Nutzer ein personalisiertes Sucherlebnis zu bieten, stellt die Suche eine besondere Herausforderung für uns dar. Sie ist auf vielfältige Weise personalisiert: Es hat nicht nur jeder Nutzer Zugriff auf einen unterschiedlichen Dokumentensatz, sondern außerdem unterschiedliche Vorlieben und Verhaltensweisen bei Suchläufen. Das steht im Gegensatz zu Web-Suchmaschinen, wo der Schwerpunkt bei der Personalisierung fast ausschließlich auf letzterem Aspekt liegt, wobei allerdings die Auswahl an Dokumenten für alle Nutzer weitgehend identisch ist (von örtlichen Besonderheiten einmal abgesehen).
Darüber hinaus ändern sich Teile der Inhalte, die wir für die Suche indexieren, recht häufig. Stellen Sie sich beispielsweise Nutzer vor, die an einem Bericht oder einer Präsentation arbeiten. Im Zuge der Erarbeitung werden immer wieder neue Versionen gespeichert, was sich auf die Suchbegriffe auswirken kann, über die das Dokument abrufbar sein sollte
Allgemein möchten wir Nutzern helfen, die jeweils relevantesten Dokumente für eine bestimmte Suchanfrage zu finden, und zwar für den aktuellen Augenblick und auf möglichst effiziente Weise. Das erfordert die Fähigkeit, sich maschinelle Intelligenz in verschiedenen Stadien in der Such-Pipeline zunutze zu machen, von inhaltsspezifischem maschinellem Lernen (wie z. B. Systeme für das Bildverständnis) bis hin zu Lernsystemen, die in der Lage sind, Suchergebnisse anhand der jeweiligen Nutzervorlieben besser einzustufen.
Solche Systeme erfordern darüber hinaus zahlreiche Iterationen, bis sie auf den Punkt gebracht werden können. Daher ist es entscheidend, mit verschiedenen Algorithmen und Subsystemen zu experimentieren und das System ganz allmählich optimieren zu können. Angesichts dieser Gegebenheiten haben wir uns zu Beginn des Nautilus-Projekts die folgenden Hauptziele gesteckt:
- Best-in-Class-Performance, -Skalierbarkeit und Zuverlässigkeit zu bieten, um unserem Datenvolumen gerecht zu werden
- Eine Grundlage für die Implementierung intelligenter Ranking- und Retrieval-Features für Dokumente zu schaffen
- Ein flexibles System zu erstellen, mit dem unsere Entwickler die Pipelines für die Indexierung und das Query Processing für laufende Experimente problemlos anpassen können
- Wie bei jedem System, das den Content der Nutzer verwaltet, musste unser Suchsystem diese Ziele rasch, zuverlässig und mit robusten Sicherungsmaßnahmen bereitstellen, um den Datenschutz für unsere Nutzer zu gewährleisten
In diesem Beitrag finden Sie eine Beschreibung der Architektur des Nautilus-Systems und seiner wichtigsten Eigenschaften, detaillierte Infos zu Entscheidungen, die wir in Bezug auf Technologien und Designansätze getroffen haben, und eine Erklärung, wie wir maschinelles Lernen (ML) in verschiedenen Stadien des Systems nutzen.
Gesamtarchitektur
Nautilus besteht aus zwei größtenteils voneinander unabhängigen Teilsystemen: Indexierung und Serving.
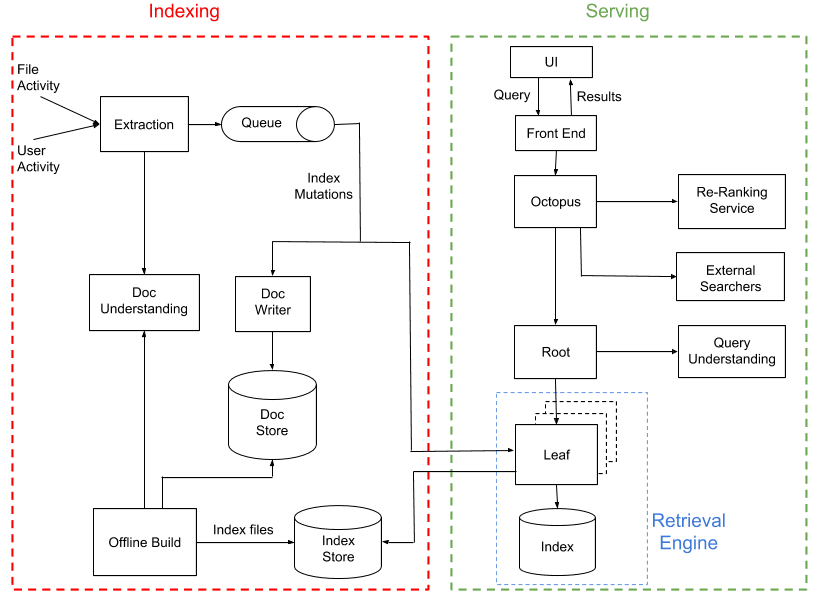
Die Rolle der Indexierungs-Pipeline ist es, die Datei- und Nutzeraktivität zu verarbeiten, Inhalt und Metadaten daraus zu extrahieren und einen Suchindex zu erstellen. Das Serving-System verwendet diesen Suchindex anschließend, um Ergebnisse als Reaktion auf Nutzerabfragen auszugeben. Zusammengenommen erstrecken sich diese Systeme über mehrere geografisch verteilte Dropbox-Rechenzentren und führen zehntausende von Prozessen auf mehr als 1.000 physischen Hosts aus.
Ein Index ließe sich am einfachsten erstellen, indem man alle Dateien in Dropbox in regelmäßigen Abständen nacheinander durchgeht und das Bereitstellungssystem so in die Lage versetzt, auf Abfragen zu reagieren. Ein solches System wäre jedoch nicht in der Lage, mit den Änderungen an Dokumenten annähernd in Echtzeit Schritt zu halten, wie es bei uns erforderlich ist. Daher verfolgen wir einen Hybridansatz, der bei Suchsystemen mit hohem Datenvolumen recht verbreitet ist:
- Wir generieren „Offline“-Builds des Suchindex (durchschnittlich alle 3 Tage).
- Im Zuge der Interaktion zwischen Nutzern und Dateien bzw. Nutzern mit anderen Nutzern, indem sie z. B. Dateien bearbeiten oder diese für andere Nutzer freigeben, generieren wir „Index-Mutationen“, die sowohl auf den Live-Index als auch einen persistenten Dokumentspeicher angewendet werden, und zwar in Echtzeit (mit einer Latenzzeit von wenigen Sekunden).
Einige der weiteren wesentlichen Elemente des Systems, die wir besprechen werden, beziehen sich darauf, wie verschiedene Arten von Inhalten indexiert werden können, unter anderem durch Verwendung von ML für das „Dokumentverständnis“ und das Ranking abgerufener Suchergebnisse (auch solchen aus anderen Suchindizes) mithilfe ML-basierter Ranking-Services.
Daten-Sharding
Bevor wir zu den konkreten Teilsystemen von Nautilus kommen, sollten wir kurz darauf eingehen, wie die nötige Skalierung zu bewerkstelligen ist. Hunderte von Milliarden von Content-Elementen stellen eine enorme Menge an Daten dar, die indexiert werden müssen. Diese werden durch das so genannte „Sharding“ über verschiedene Geräte verteilt. Dazu muss entschieden werden,, wie wir Dateien so aufteilen können, dass Suchabfragen aller Nutzer schnell abgeschlossen werden, während die Last gleichzeitig relativ gleichmäßig über alle Geräte verteilt wird.
Bei Dropbox haben wir bereits ein solches Schema für die Dateigruppierung, einen sogenannten „Namespace“ (Namensraum), den man sich als Ordner vorstellen kann, auf den bestimmte Nutzer zugreifen können. Zu den Vorteilen dieses Ansatzes zählt, dass wir auf diese Weise nur Suchergebnisse für Dateien ausgeben können, auf die der Nutzer Zugriff hat. So können wir außerdem freigegebene Ordner berücksichtigen. Ein Beispiel: Der Ordner wird zu einem neuen Namespace, auf den sowohl der freigebende Nutzer als auch der Empfänger der Freigabe zugreifen kann. Auf welche Dateien Dropbox-Nutzer jeweils zugreifen können, wird umfassend durch die Namespaces definiert, auf die ihnen Zugriff erteilt wurde. Angesichts der aufgeführten Eigenschaften von Namespaces müssen wir alle Namespaces durchsuchen, auf die Nutzer Zugriff haben, und alle passenden Ergebnisse zusammenführen, wenn ein Suchbegriff eingegeben wird. Das bedeutet gleichzeitig, dass wir nur solche Inhalte durchsuchen, auf die der abfragende Nutzer zu dem Zeitpunkt Zugriff hat, zu dem die Suche durchgeführt wird, indem wir die Namespaces an das Suchsystem übergeben.
Dabei wird eine Reihe von Namespaces in einer sogenannten „Partition“ zusammengeführt – die logische Einheit, über die wir Daten speichern, indexieren und schließlich bereitstellen. Dazu verwenden wir ein Partitionierungssystem, mit dem wir Namespaces auch zukünftig leicht neu partitionieren können, wenn sich der Bedarf ändert. Derzeit haben wir 2.048 Partitionen.
Indexieren
Dokumentextraktion und -verständnis
Wonach möchten Nutzer gerne suchen? Natürlich gibt es da den Inhalt des jeweiligen Dokuments, also z. B. den Text in einer Datei. Aber es gibt auch zahlreiche andere Arten von relevanten Daten und Metadaten.
Wir haben Nautilus so konzipiert, dass das System all diese Inhalte und vieles mehr flexibel handhaben kann, und zwar durch die Möglichkeit zur Definition einer Reihe von „Extraktoren“, die aus der Eingabedatei eine bestimmte Art von Output extrahiert und diese in eine Spalte in unserem „Dokumentspeicher“ einträgt. Der Speicher basiert auf der HBase-Technologie, wobei wir zusätzliche, eigens erstellte Ebenen für die Zugriffskontrolle und die Datenverschlüsselung darauf aufgebaut haben. Diese Technologie enthält pro Datei eine Zeile, wobei jede Spalte den Output eines bestimmten Extraktors enthält. Ein wesentlicher Vorteil dieses Schemas ist, dass wir ganz einfach mehrere Spalten in einer Zeile parallel aktualisieren können, ohne uns darüber Sorgen machen zu müssen, dass Änderungen an einem Extraktor die Ergebnisse anderer Extraktoren beeinträchtigen.
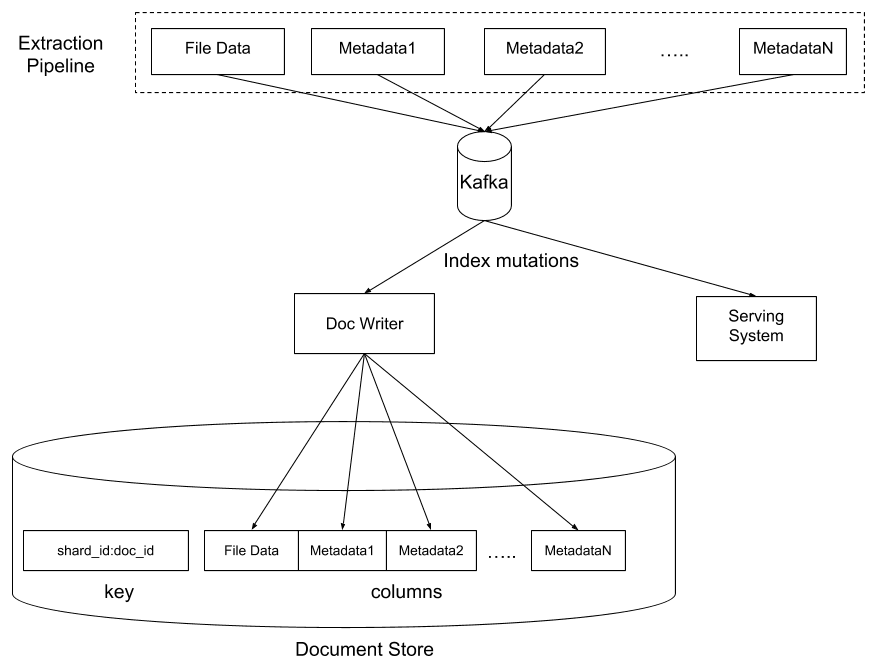
Für die meisten Dokumente verlassen wir uns auf Apache Tika, um das Originaldokument in eine kanonische HTML-Darstellung umzuwandeln, die dann analysiert wird, um eine Liste von „Tokens“ (also Wörtern) sowie deren „Attribute“ (also Formatierung, Anordnung usw.) zu extrahieren.
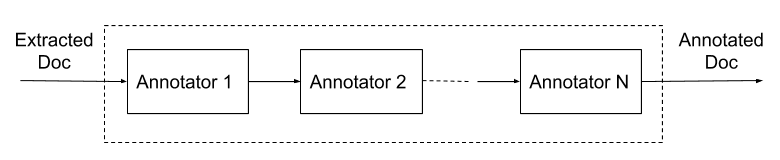
Nach der Extraktion der Tokens können wir die Daten auf unterschiedliche Weise mittels einer Pipeline für das „Dokumentverständnis“ ergänzen, die sich gut zum Ausprobieren der Extraktion optionaler Metadaten und Signale eignet. Als Input dienen die aus dem Dokument selbst extrahierten Daten. Ausgegeben wird ein Satz zusätzlicher Daten, die wir als „Annotationen“ bezeichnen. Plugin-Module, so genannte „Annotatoren“, sind für das Erzeugen der Annotationen zuständig. Ein Beispiel eines einfachen Annotators ist das Stemming-Modul, das aus unbearbeiteten Tokens gestemmte Tokens erzeugt. Ein weiteres Beispiel ist die Umwandlung von Tokens in Einbettungen für eine flexiblere Suche.
Offline-Builds
Der Dokumentspeicher enthält den gesamten Suchkorpus, ist jedoch nicht gut für die Ausführung von Suchläufen geeignet. Das liegt daran, dass darin extrahierter, nach Dokument-ID zugeordneter Content gespeichert wird. Für die Suche benötigen wir jedoch eine invertierte Datei: Die Zuordnung (Mapping) vom Suchbegriff zu einer Liste von Dokumenten. Der regelmäßige Neuaufbau dieses Suchindex aus dem Dokumentspeicher erfolgt über das Offline-Build-System. Dabei wird das Äquivalent eines MapReduce-Jobs für den Dokumentspeicher durchgeführt, um einen Suchindex zu erstellen, der extrem schnell abgefragt werden kann. Jede Partition ist am Ende mit einer Reihe von Indexdateien ausgestattet, die in einem HDFS-basierten „Index Store“ aufbewahrt werden.
Das Loslösen des Vorgangs der Dokumentextraktion von der Indexierung schafft eine Menge Flexibilität für Experimente:
- Modifizierung des internen Formats des Index selbst, einschließlich der Fähigkeit, mit einem neuen Indexformat zu experimentieren, das die Abrufleistung verbessert und die Speicherkosten reduziert.
- Anwendung eines neuen Dokument-Annotators auf den gesamten Korpus. Nachdem ein Annotator Vorteile bei der Anwendung auf die neuen Dokumente in der Pipeline für die Sofortindexierung gezeigt hat, kann er in wenigen Tagen auf den gesamten Dokumentkorpus angewendet werden. Dazu wird er einfach zur Offline-Build-Pipeline hinzugefügt. Das steigert die Experimentiergeschwindigkeit im Vergleich zur Notwendigkeit, umfassende Abgleichsskripte zur Aktualisierung des Datenkorpus im Dokumentspeicher ausführen zu müssen.
- Verbesserte Heuristik beim Filtern indexierter Daten. Es ist nicht überraschend, dass wir beim Umgang mit Hunderten von Millionen von Inhalten das System vor Ausnahmefällen schützen müssen, die eine Verschlechterung der Präzision oder der Leistung herbeiführen könnten, wie es beispielsweise bei extrem großen oder fehlerhaft analysierten Dokumenten der Fall wäre, die degradierte Tokens erzeugen. Uns stehen verschiedene heuristische Methoden zum Herausfiltern dieser Dokumente aus dem Index zur Verfügung, die wir problemlos nach und nach aktualisieren können, ohne dazu jedes Mal die Quelldokumente neu verarbeiten zu müssen.
Minimierung unvorhergesehener Probleme aufgrund neuer Experimente. Im Falle eines Fehlers bei der Indexierung können wir einfach auf eine vorherige Version des Index zurückgreifen. Dieser Sicherungsmechanismus sorgt in der Praxis für eine höhere Risikotoleranz und eine höhere Iterationsgeschwindigkeit beim Experimentieren.
Serving (Datenbereitstellung)
Das Datenbereitstellungssystem besteht aus einem Frontend, das Suchanfragen von Nutzern annimmt und weiterleitet, einer Retrieval Engine, die eine umfassende Liste passender Dokumente für jede Anfrage abruft, sowie dem Ranking-System „Octopus“, das Ergebnisse von mehreren Backends mittels maschinellem Lernen einstuft. Hier konzentrieren wir uns auf letztere, da das Frontend aus einer recht unkomplizierten Reihe von APIs besteht, die all unsere Kunden verwenden (Web, Desktop, Mobilgeräte).
Retrieval Engine
Dabei handelt es sich um ein verteiltes System, das Dokumente abruft, die einer Suchanfrage entsprechen. Diese Engine ist für hohe Leistung und eine hohe Trefferquote optimiert – sie versucht, die größtmögliche Liste von Kandidaten innerhalb des vorgegebenen Zeitbudgets auszugeben. Diese Ergebnisse werden dann von Octopus, unserer Suchföderationsebene, in eine Reihenfolge gebracht, um hohe Präzision zu erzielen, d. h. sicherzustellen, dass die relevantesten Ergebnisse ganz oben in der Liste aufgeführt werden. Die Abrufengine ist als Suchbaum in „Blätter“ und eine „Wurzel“ gegliedert:
- Die Wurzel ist primär dafür zuständig, eingehende Anfragen an die „Blätter“ zu verteilen, in denen die Daten abgelegt sind, und anschließend die Ergebnisse von den Blättern zu empfangen und zusammenzuführen, bevor sie an Octopus zurückgeleitet werden.
- Außerdem umfasst die Wurzel eine Pipeline für das „Abfrageverständnis“, die der oben besprochenen Pipeline für das „Dokumentverständnis“ stark ähnelt. Das dient dazu, eine Abfrage umzuwandeln bzw. zu annotieren, um Abrufergebnisse zu verbessern.
Jedes Blatt handhabt die eigentliche Dokumentsuche für eine Gruppe von Namespaces. Es verwaltet den invertierten und den vorwärtsgerichteten Dokumentenindex. Der zugrundeliegende Datenspeicher für den Index ist RocksDB. Der Index wird regelmäßig neu angelegt, indem ein Build aus dem Offline-Build-Prozess heruntergeladen wird. Anschließend wird er kontinuierlich durch die Anwendung von Mutationen aus Kafka-Warteschlangen aktualisiert.
Suchorchestrierung
Unsere Suchorchestrierungsebene heißt Octopus. Nach Erhalt einer Nutzeranfrage ruft Octopus zunächst den Zugriffssteuerungsdienst (Access Control Service) von Dropbox auf, um festzustellen, auf welche Namespaces der Nutzer genau Zugriff hat. Diese Gruppe von Namespaces gibt den „Umfang“ der Abfrage vor, die von der nachgeschalteten Retrieval Engine durchgeführt wird, sodass nur für den Nutzer verfügbare Inhalte durchsucht werden.
Neben der Abfrage von Ergebnissen aus der Retrieval-Engine Nautilus sind noch einige andere Dinge erforderlich, bevor dem Nutzer ein fertiger Satz von Ergebnissen ausgegeben wird:
- Föderierung: Zusätzlich zu unserer primären Dokumentspeicher- und Abruf-Engine (oben beschrieben), nutzen wir einige getrennte Zusatz-Backends, die für bestimmte Arten von Content abgefragt werden müssen. Ein Beispiel hierfür sind Dropbox Paper-Dokumente, die derzeit in einem getrennten Stapel ausgeführt werden. Octopus bietet die Flexibilität, Suchanfragen an mehrere Backend-Suchmaschinen zu schicken und die Ergebnisse zusammenzuführen.
- Schatten-Engines: Die Möglichkeit, Ergebnisse von mehreren Backends auszugeben, ist außerdem äußerst nützlich, wenn es darum geht, Updates am Backend unserer primären Retrieval Engine auf die Probe zu stellen. Während der Validierungsphase können wir Suchabfragen sowohl an das Produktionssystem als auch an das neue System ausgeben, das getestet wird. Das wird oft als „Schatten“-Datenverkehr bezeichnet. Nur Ergebnisse aus dem Produktionssystem werden an den Nutzer ausgegeben, doch Daten aus beiden Systemen werden zur weiteren Analyse protokolliert, z. B. für den Vergleich von Suchergebnissen oder der Messung von Leistungsunterschieden.
- Ranking: Nach dem Erfassen der Liste der Kandidatendokumente aus den Search-Backends ruft Octopus bei Bedarf zusätzliche Signale und Metadaten ab, bevor es diese Informationen an einen separaten Ranking-Dienst sendet, der seinerseits die Scores berechnet, aus denen die schließlich an den Nutzer ausgegebene Ergebnisliste erstellt wird.
Überprüfung der Zugriffskontrolle (ACL): Zusätzlich zur Einschränkung der Suche auf die im Abfrageumfang definierten Namespaces durch die Retrieval Engine wird auf der Octopus-Ebene eine zusätzliche Schutzebene eingezogen, indem erneut überprüft wird, ob der abfragende Nutzer auf jedes von der Engine ausgegebene Ergebnis zugreifen kann.
Dabei muss beachtet werden, dass all diese Schritte sehr schnell ablaufen müssen: Unser Zeitbudget beträgt 500 Millisekunden für die Suche im 95ten Perzentil vor (d. h. nur 5 % der Suchläufe dürfen jemals länger als 500 Millisekunden dauern). In einem zukünftigen Beitrag erklären wir, wie das geht.
Auf maschinelles Lernen gestütztes Ranking
Wie zuvor erwähnt wird unsere Retrieval Engine so getunt, dass ein großer Satz passender Dokumente ausgegeben wird, ohne dass wir uns zunächst allzu große Sorgen darüber machen, wie relevant die einzelnen Dokumente für den Nutzer sind. Im Ranking-Schritt liegt der Schwerpunkt auf dem anderen Ende des Spektrums: Es geht um die Auswahl der Dokumente, die der Nutzer am ehesten jetzt sofort nutzen will. (Technisch ausgedrückt ist die Retrieval Engine für die Trefferquote optimiert, das Ranking-System dagegen für Genauigkeit.)
Die Ranking-Engine basiert auf einem ML-Modell, das jedem Dokument auf Grundlage verschiedener Signale einen Score zuweist. Einige Signale messen die Relevanz eines Dokuments für die Anfrage (z. B. BM25), während andere die Relevanz des Dokuments für den Nutzer zum aktuellen Zeitpunkt messen (z. B. mit wem Nutzer interagiert haben oder welche Art von Dateien sie genutzt haben).
Das Modell wird mittels anonymisierter „Klick“-Daten aus unserem Frontend trainiert, das personenbezogene Daten ausschließt. Vorherige Suchabfragen und das Betrachten der angeklickten Ergebnisse geben dabei Aufschluss über allgemeine Relevanzmuster. Darüber hinaus wird das Modell häufig neu trainiert bzw. aktualisiert, sodass im Laufe der Zeit eine Anpassung und ein Lernen anhand des allgemeinen Nutzerverhaltens stattfindet.
Der Hauptvorteil einer ML-basierten Ranking-Lösung ist, dass wir eine große Zahl von Signalen verwenden und neue Signale automatisch verarbeiten können. So könnte man theoretisch die „Wichtigkeit“ aller verfügbaren Signaltypen auch manuell festlegen und sie z. B. danach einstufen, welche Dokumente der Nutzer zuletzt aufgerufen oder bearbeitet hat oder oft das Dokument die Suchbegriffe beinhaltet. Dieser Ansatz wäre denkbar, wenn nur eine Handvoll von Signalen zur Verfügung stünde. Doch beim Hinzufügen von Dutzenden, Hunderten oder sogar Tausenden von Signalen kann eine manuelle Festlegung unmöglich auf effiziente Weise geschehen. Genau hier zeigen sich die Stärken des ML: Es kann automatisch den richtigen Satz von „Bedeutungsgewichtungen“ für das Ranking von Dokumenten lernen, sodass dem Nutzer die relevantesten Ergebnisse angezeigt werden. Beispielsweise konnten wir im Zuge unserer Experimente feststellen, dass Aktualitäts-bezogene Signale signifikant zu relevanteren Ergebnissen beitragen.
Fazit
Nach einer Qualifizierungsphase, in der Nautilus im Schattenmodus ausgeführt wurde, ist es nun die primäre Suchmaschine bei Dropbox. Wir konnten bereits erhebliche Verbesserungen bezüglich der Zeit für die Indexierung neuer und aktualisierter Inhalte konstatieren und es steht noch vieles Weitere an.
Da wir nun eine solide Grundlage geschaffen haben, ist unser Team damit beschäftigt, auf der Nautilus-Plattform aufzubauen, um neue Features hinzuzufügen und die Suchqualität zu verbessern. Wir erkunden neue Funktionen wie z. B. das Erweitern des bestehenden Retrieval-Algorithmus mit Posting-Listen durch ein distanzbasiertes System mit einem Einbettungsraum, die Möglichkeit zur Suche nach Bild-, Video- und Audiodateien mittels automatischem Tagging und die verbesserte Personalisierung mittels zusätzlicher Nutzeraktivitätssignale und vieles mehr.
Nautilus ist ein führendes Beispiel für die Art von umfangreichen Projekten, die mit Datenabruf und maschinellem Lernen zu tun haben, an denen Entwickler bei Dropbox arbeiten. Wenn Sie sich für Fragestellungen dieser Art interessieren, würden wir Sie gerne Sie in unserem Team begrüßen.




