Leistungsüberprüfung und Zuverlässigkeit der neuen Dropbox-Suchmaschine

In unserem vorherigen Post ging es um die Architektur und die ML-Features der neuen Nautilus-Suchmaschine. In diesem Beitrag möchten wir uns dem Prozess widmen, mit dem wir optimale Performance und Zuverlässigkeit erzielt haben.
Leistung
Indexformat
Jedes einzelne unserer Suchblätter (von denen es Hunderte gibt), aktiviert die Retrieval Engine, die unter anderem den Index beim Erstellen, Bearbeiten und Löschen von Dateien (also bei Schreibvorgängen) aktualisiert und Suchanfragen ausführt (also Lesevorgänge durchführt). Charakteristisch für den Datenverkehr bei Dropbox ist die Dominanz von Schreibvorgängen; Dateien werden weitaus häufiger aktualisiert als gesucht. In der Regel beobachten wir ein zehnmal höheres Schreib- als Lesevolumen. Daher haben wir diese Workloads sorgfältig beim Optimieren der Datenstrukturen abgewogen, die für die Retrieval Engine verwendet werden.
Eine „Posting-Liste“ ist eine Datenstruktur, die der Liste der Dokumente ein Token (also einen potenziellen Suchbegriff) zuweist, die dieses Token beinhalten. Im Wesentlichen hat eine Retrieval Engine hauptsächlich die Aufgabe, eine Reihe von Posting-Listen zu pflegen, welche die invertierte Datei darstellen. Posting-Listen werden im Zuge von Suchanfragen abgefragt und aktualisiert, wenn der Index aktualisiert wird. Bei einem verbreiteten Posting-Listen-Format wird das Token und eine zugehörige Liste von Dokument-IDs neben einigen Metadaten gespeichert, die während der Scoring-Phase verwendet werden können (z. B. Begriffshäufigkeit).

Dieses Format ist ideal für Workloads, die primär schreibgeschützt sind. Jede Suchanfrage erfordert lediglich das Auffinden des passenden Satzes von Posting-Listen (dabei kann es sich um O(1) mit einer Hashtabelle handeln), wobei die übrigen verbundenen Dokument-IDs dann jeweils zum Ergebnissatz hinzugefügt werden.
Um die häufige Aktualisierung von Inhalten zu bewältigen, die wir bei unseren Nutzern beobachtet haben, haben wir jedoch für eine „Explosionsdarstellung“ für das Posting-Listenformat in der invertierten Datei entschieden. Unser invertierter Index wird durch einen Schlüssel-/Wertspeicher (RocksDB) gestützt und jedes (Namespace-ID-, Token-, Dokument-ID-) Tupel wird als getrennte Zeile aufbewahrt. Konkret lautet das Format eines Zeilenschlüssels „<Namespace-ID>|<Token>|<Dokument-ID>“. Bei einer Suchanfrage für Dokumente in einem bestimmten Namespace können wir effizient eine Präfixsuche nach <Namespace-ID><Token>| im Index ausführen, um eine Liste aller passenden Dokumente abzurufen. Die Integration des Namespace-Konzepts in das Format des Schlüssels hat mehrere Vorteile. Erstens – und das ist besonders wichtig – wird so im Hinblick auf Sicherheit jede Möglichkeit verhindert, dass eine Anfrage Dokumente außerhalb des angegebenen Namespace ausgibt, auf den der Nutzer Zugriff hat. Zweitens wird die Leistung beeinflusst, da die Suche ausschließlich auf die Dokumente im Namespace begrenzt ist und sie die übrigen Dokumente, die in der Partition indexiert sind, ausschließt. So werden die mit dem Token verknüpften Metadaten mit dem Wert der jeweiligen Zeile verknüpft.
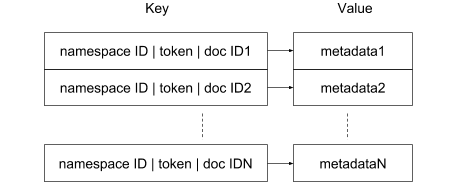
Im Hinblick auf das Speichern und Abrufen (Retrieval) ist dies weniger effizient als das konventionelle Format, bei dem alle Dokument-IDs gruppiert sind und mit Methoden wie der Delta-Verschlüsselung in einer kompakten Darstellung gespeichert werden können. Doch diese „Explosionsdarstellung“ hat einen wesentlichen Vorteil: Sie kann Index-Mutationen besonders effizient handhaben. Beispielsweise wird ein Dokument zur invertierten Datei hinzugefügt, indem eine Zeile für jedes enthaltene Token eingefügt wird. Dieses einfache Verfahren erzielt für die meisten Schlüssel-/Wertspeicher – auch für RocksDB – sehr gute, effiziente Ergebnisse. Der zusätzliche Speicheraufwand wird durch die Tatsache aufgewogen, dass RocksDB eine Präfix-Komprimierung auf Schlüssel anwendet. Insgesamt haben wir daher festgestellt, dass die Indexgröße bei der Explosionsdarstellung nur etwa 15 % größer war als bei einer konventionellen Posting-Listen-Darstellung.
Serving (Datenbereitstellung)
Eine schnelle Ansprache ist für eine reibungslose, interaktive Nutzererfahrung unverzichtbar. Die primäre Kennzahl, die wir zur Beurteilung der Server-Performance nutzen, ist die Abfragelatenz im 95sten und 99sten Perzentil, d. h. die langsamsten 5 % bzw. 1 % der Abfragen dürfen maximal 500 Millisekunden bzw. 1 Sekunde dauern (aktuell). Die mediane Abfragegeschwindigkeit ist natürlich erheblich höher. Mit fortschreitender Entwicklung des Nautilus-Systems haben wir die Performance unaufhörlich gemessen und analysiert. Jede Systemkomponente wird geprüft, um festzustellen, wie viel sie zur Gesamtlatenz beiträgt. Dabei haben wir einiges gelernt, unter anderem Folgendes:
- Allzu frühe Optimierung ist nicht ideal: Wir haben die Performance der Retrieval Engine erst dann optimiert, als wir uns genau darüber im Klaren waren, wie jede einzelne Systemkomponente zur Gesamtlatenz beitrug. Auf den ersten Blick hätte man erwarten können, dass die Retrievalphase am längsten dauert. Nach einer ersten Analyse der Daten stellten wir jedoch fest, dass ein erheblicher Teil der Latenz durch das Abrufen von Metadaten aus externen Systemen zur Überprüfung von ACLs und zur „Verschönerung“ der Suchergebnisse vor der Ausgabe verursacht wurde, die relationale Datenbanken nutzten. Dazu zählen Dinge wie das Aufführen des Ordnerpfads, des Autors, des Zeitpunkts der letzten Bearbeitung usw.
- Die „Query of Death“ hat ihren Namen verdient: Ein paar wenige, schädliche Anfragen, die auch als „Query of Death“ – also „tödliche Abfrage“ – bezeichnet werden, können sich sehr negativ auf die Gesamtlatenz auswirken. Diese werden meist durch Fehler in Software verursacht, die auf die Such-API programmiert ist, und nicht durch menschliche Nutzer. Daher haben wir „Schutzschalter“ eingebaut, die diese Anfragen herausfiltern, um das Gesamtsystem zu schützen. Außerdem haben wir die Möglichkeit geschaffen, ein „Zeitbudget“ vorzugeben, sodass die Retrieval Engine aufhört, Kandidaten für eine Anfrage abzurufen, sobald die gesetzte Zeit überschritten wird. Dies erwies sich als gut für die Performance und die Systemauslastung insgesamt, führt allerdings dazu, dass nicht immer alle möglichen Ergebnisse ausgegeben werden. Das ist meist bei sehr breitangelegten Anfragen mit vielen Treffern der Fall – z. B. bei einer Präfix-Suche für ein einzelnes Token (wie es bei der automatischen Vervollständigung von Suchanfragen geschieht).
- Replikation verbessert auch die Tail-Latenz: Unsere Blätter werden 2x repliziert, um Redundanzen zu schaffen, für den Fall, dass Probleme beim Gerät auftreten. Diese Replikationen bieten jedoch auch einen Leistungsvorteil: Sie können zur Verbesserung der sogenannten Tail-Latenz dienen (d. h. der Latenz der langsamsten Anfragen). Wir verwenden die bekannte Methode des Sendens einer Anfrage an alle Replikationen und der Ausgabe der schnellsten Antwort.
- Es lohnt sich, in den Aufbau von Benchmarking-Tools zu investieren: Sobald eine bestimmte Komponente als Leistungsengpass identifiziert wird, ist das Erstellen von Benchmarking-Tools für Belastungstests und zur Leistungsmessung der jeweiligen Komponente eine gute Methode, eine schnelle Iteration bei der Leistungsverbesserung zu erzielen, sodass nicht immer das gesamte System getestet werden muss. Wir setzen ein Benchmark-Tool für die primäre Retrieval-Engine ein, die in den Blättern ausgeführt wird. Damit messen wir die Indexierungs- und Retrieval-Leistung der Engine auf Partitionsebene anhand synthetischer Daten. Die Partitionsdaten werden so generiert, dass sie produktionsnahe Eigenschaften in Bezug auf die Gesamtzahl der Namespaces, Dokumente, Tokens sowie die Verteilung der Zahl der Dokumente pro Namespace und die Zahl der Tokens pro Dokument aufweisen.
Zuverlässigkeit
Millionen von Nutzern verlassen sich auf die Dropbox-Suche, um ihre Arbeit zu erledigen. Daher haben wir beim Entwickeln des Systems besonders darauf geachtet, dass wir die verfügbare Betriebszeit garantieren konnten, die unsere Nutzer erwarten.
IIn einem großen, verteilten System kommt es regelmäßig zum Ausfall von Systemen und Hardware und zum Absturz von Software – das ist unvermeidlich. Diese Tatsache haben wir bei der Konzipierung von Nautilus im Hinterkopf behalten und daher den Schwerpunkt speziell auf die Fehlertoleranz und die automatische Wiederherstellung von Komponenten im Bereitstellungspfad gelegt.
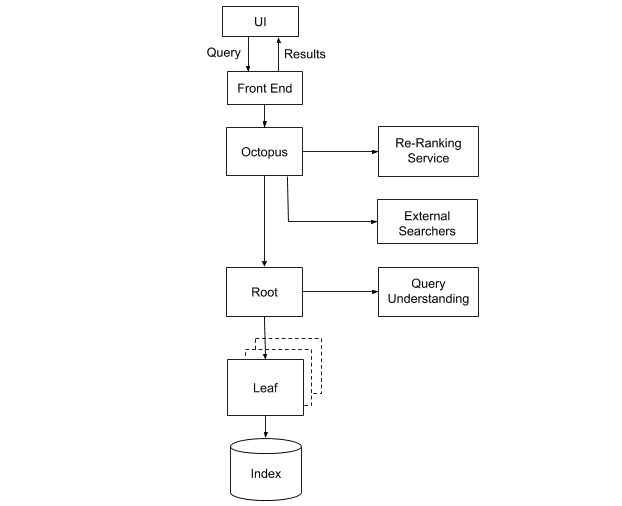
Einige der Komponenten wurden als zustandslose Komponenten konzipiert, d. h. zur Ausführung sind keine externen Dienste oder Daten erforderlich. Dazu zählen auch Octopus, unser System für die Zusammenführung und Einstufung von Ergebnissen, sowie die Wurzel der Retrieval Engine, die Suchanfragen auf sämtliche Blätter verteilt. Diese Dienste können somit problemlos mit mehreren Instanzen verfügbar gemacht werden, die bei einem Ausfall jeweils automatisch neu bereitgestellt werden können. Das Problem stellt eine größere Herausforderung in Bezug auf die Blatt-Instanzen dar, da die Indexdaten hier gepflegt werden.
Partitionszuweisung
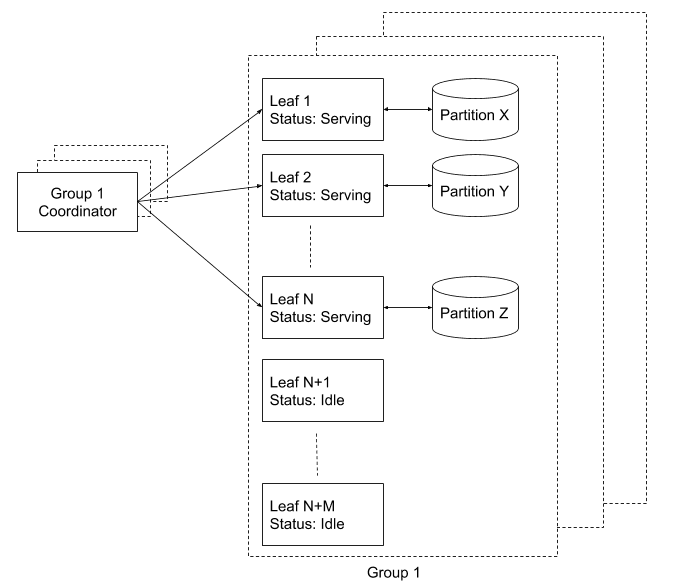
In Nautilus ist jede Blattinstanz für die Handhabung eines Teils des Suchindex zuständig, die so genannte „Partition“. Wir pflegen eine Registerdatei aller Blätter und weisen ihnen mit einem getrennten Koordinator Partitionen zu (gestützt durch Zookeeper). Der Koordinator ist dafür zuständig, die kontinuierliche Abdeckung sämtlicher Partitionen (100 %) zu gewährleisten. Wenn eine neue Blattinstanz aufgerufen wird, bleibt sie inaktiv, bis sie vom Koordinator angewiesen wird, eine Partition zu bedienen. Zu diesem Zeitpunkt lädt sie den Index und fängt an, Suchanfragen zu akzeptieren.
Was geschieht, wenn ein Blatt dabei ist, online zu gehen, aber eine Suchanfrage für Daten in der betreffenden Partition eingeht? Das bewältigen wir, indem wir Replikationen der einzelnen Blätter pflegen, die zusammen als „Blattreplikationsgruppen“ bezeichnet werden. Bei einer Gruppe von Replikationen handelt es sich um einen unabhängigen Cluster von Blattinstanzen, die den Index komplett abdecken. Beispielsweise führen wir zwei Gruppen von Replikationen mit einem Koordinator für jede Gruppe aus, um eine zweifache Systemreplikation zu gewährleisten. Das macht nicht nur die Diskussion über die Replikation einfach, sondern bietet außerdem operative Vorteile für die Wartung, wie z. B.:
- Neuer Code kann ohne Auswirkungen auf die Verfügbarkeit in das Produktionssystem übernommen werden, indem er einfach erst für eine Gruppe und dann die nächste bereitgestellt wird.
- Es ist möglich, eine komplette Gruppe hinzuzufügen oder zu entfernen. Dies ist besonders bei Hardware- und Betriebssystem-Upgrades nützlich. Beispielsweise kann eine Gruppe hinzugefügt werden, die auf neuer Hardware läuft, und – sobald diese voll einsatzfähig ist – können wir die Gruppe dekommissionieren, die auf der älteren Hardware ausgeführt wird.
In beiden Fällen kann Nautilus sämtliche Anfragen umfassend über den gesamten Prozess hinweg beantworten.
Wiederherstellung
Jede Blattgruppe ist mit etwa. 15 % zusätzlicher Hardwarekapazität überprovisioniert, damit ein Pool ungenutzter Instanzen stets zugeschaltet werden kann. Wenn der Koordinator einen Rückgang der Partitionsabdeckung entdeckt (wenn z. B. ein derzeit aktives Blatt keine Anfragen mehr ausgibt), weist er ein ungenutztes Blatt an, die betreffende Partition zu bedienen. Das Blatt führt dann die folgenden Schritte aus:
- Es lädt die mit der Partition verknüpften Indexdaten aus dem Index-Repository herunter. Damit hat es einen veralteten Index, der vor einiger Zeit durch das Offline-Build-System erzeugt wurde.
- Nun werden alte Mutationen aus der Kafka-Warteschlange angewendet, angefangen bei dem Offset, an dem die Index-Partition erstellt wurde.
- Nachdem diese älteren Mutationen auf den heruntergeladenen Index angewendet worden sind, ist der Blatt-Index auf dem aktuellen Stand. Zu diesem Zeitpunkt wechselt das Blatt in den Bereitstellungsmodus und fängt an, Abfragen zu verarbeiten.




